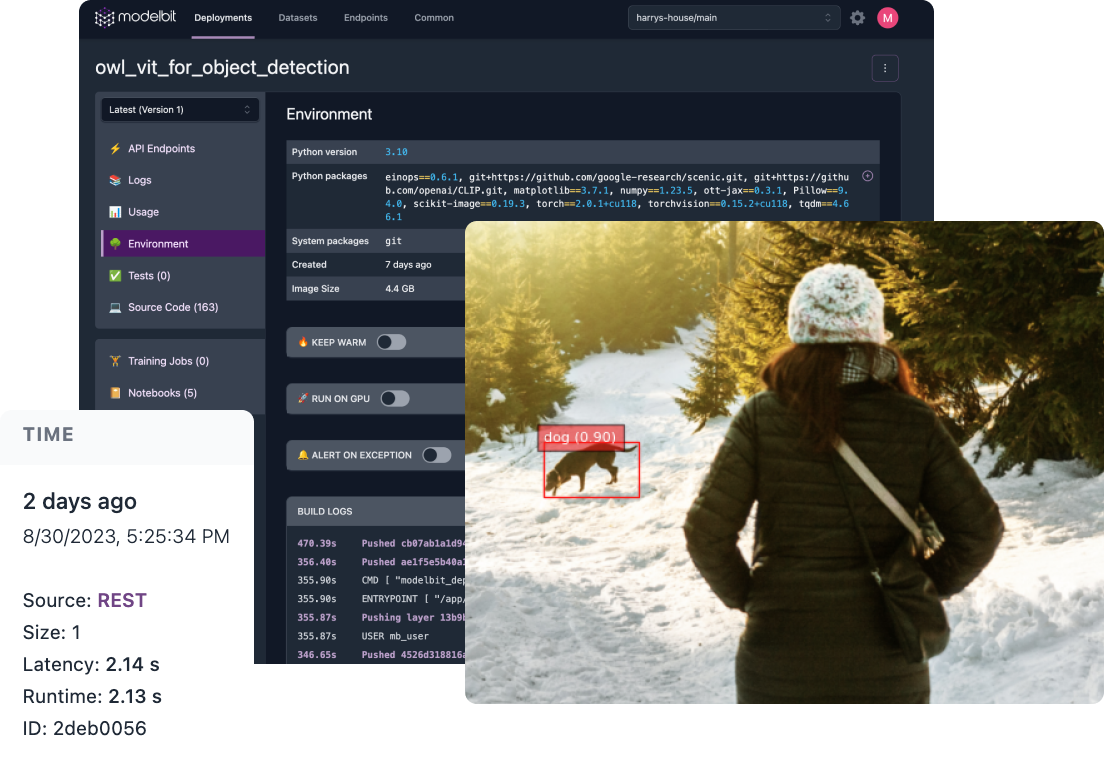
OWL-ViT is an open-vocabulary object detector developed by the team at Google Research. Given an image and one or multiple free-text queries, it finds objects matching the queries in the image. Unlike traditional object detection models, OWL-ViT is not trained on labeled object datasets and leverages multi-modal representations to perform open-vocabulary detection.
In an earlier
blog post, we walked though the steps to deploy an OWL-ViT model to a REST Endpoint using Modelbit.
In the demo below, you can interact with an OWL-ViT model that has been deployed with Modelbit. Click on an image to get started!